
每天都要喝牛奶
这本书主要阐释的观点:语言和数学的产生都是为了同一个目的——记录和传播信息。
前序
在大学前两年学过的数学知识,当时真的不知道用途何在,日常用不上,编程的时候,更多的注重于技术和逻辑,心里不禁对数学有些轻视感。看了吴军博士写的《数学之美》后,发现数学能够降低问题的复杂性,日常所用到的搜索和打字输入法,都有数学模型的存在,而且还了解到许多有趣的数学家生活故事。
嗯,可以说,看完这本书,会重新激发起对数学的兴趣。
简介
书中介绍了吴军在Google、腾讯的工作经历,给我们介绍了关于搜索引擎、语音识别的基础设计原理,还涉及到PageRank(网页排名技术)、状态机、余弦定理实际运用、数学模型、信息最大熵、自然语言处理、马尔科夫链和贝叶斯网络等等方面的原理。
而且吴军在前面的章节中,讲解的内容深入浅出,思路很清晰,体现出作者深厚的功力。而在后面的专业章节中,深入介绍数学,讲解算法,进一步提高我们的思维高度。虽然数学知识忘得差不多,但看起来并不会很吃力,主要是作者举的例子、语言描述和图片的搭配恰到好处。
我还没有这么强的数学能力,但还是想要给大家介绍这本书,就拿第一章介绍,给大家一个安利。
信息的传递
在通信方式中,古时的人和我们今天的通讯模型没有什么不同,都与下图类似:
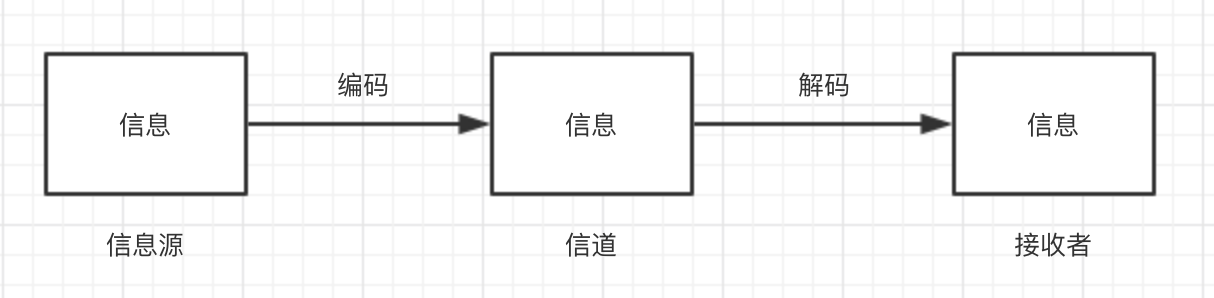
当时初高中在学文言文的时候,就发现中国古代语言的深奥,简单的一句话可以包含不同的意思,在看这本书的时候(在第二版P11),才发现答案:
在蔡伦发明纸张之前,数学文字不是一件容易的事情。就以中文为例,在东汉以前要将文字刻在其他物件比如龟壳石碑和竹简上。由于刻一个的时间相当长,因此要惜墨如金。这就使得我们的古文(书面文字)非常简洁,但是也非常难懂,而同时期的口语却和今天的白话差别不大,语句较长但是难懂。(岭南客家话基本保留了古代口语的原貌,写出来和我们清末民初的白话颇为相似。)
然后简单总结了:在通信时,如果信道较宽,信息不必压缩就可以直接传递;而如果信道很窄,信息在传递前需要尽可能地压缩,然后在接收端进行解压缩。在古代,两个人说话说得快是一个宽信道,无需压缩;书写慢是一个窄通道,需要压缩。将日常的白话口语书写成精简的文言文就是信道压缩的过程,而将文言文解释清楚是解压缩的过程。(看来我是解压缩过程中出错了,高中语文多数跪在文言文手上👻)
信息的载体
古埃及人不仅是优秀的农夫和建筑师,他们还发明了最早的保存信息的方式-用图形保存事物,这就是最早的象形文字(Hieroglyphic)。例如古埃及的《亚尼的死者之书》,是一副描绘在纸莎草纸上长达20多米的长卷,是随葬品,放在棺中,可以看做是古埃及死者带到另一个世界的介绍信和今后生活的描述,下图来源百度:

但是随着文明的进步,信息量也逐渐增加,因为没有人能够学会和记住这么多文字,埃及的象形文字数量便不再继续增加了。于是,概念的第一次概括和归类就开始了。例如汉字中,“日”本意是太阳,但它同时又是太阳从升起再到升起的时间周期。(大概“日”字旁的汉字都与太阳有关。)这种概念的聚类,在原理上与今天自然语言处理或者机器学习的聚类有很大的相似性。
同时,文字按照意思来聚类,最终会带来一些歧义性,这时就要根据上下文进行分析。现在使用的输入法,基本都有建立上下文模型,在输入一段文字后,会根据上下文带出下一段内容供用户选择,各个输入法都在不断完善,训练模型争取超越对方。
还有一个🌰,是在罗塞塔(Rosetta)的地方发现的一块破碎的古埃及石碑,上面记录了三种语言:埃及象形文字、埃及的拼音文字和古希腊文。考古学家进行拓印,在学者手中传阅,最终得以将古埃及象形文字破解。可见不管是石碑还是拓片,它所承载的信息才是最总要的。
数字
数学是我们从小学就开始学习的学科之一,但当时还不知道数学的历史,也遗憾没能发现它的美。
数字是技术系统的基础,早期数字并没有书写的形式,而是掰指头,这就是我们今天使用十进制的原因。在早期,人类将数字一道道地刻在木头、骨头或者其他便于携带的物件上,考古学家在斯威士兰和南非之间的乐邦博(Lebombo)发现几根35000年前的狒狒腓骨,上面有用于计数的划痕。说明在35000年前,人类就开始有了计数系统。
人类第二个文明的中心:两河流域的美索不达米亚,诞生了楔形文字(我们这个星球上最古老的拼音文字),出现了楔(xie)子点,用来表示数字,如下图:
(一看到美索不达米亚和楔形字,就会想到周杰伦的《爱在西元前》,方文山和周杰伦是多有才啊!!!)
同样,计数越来越大之后,十个指头已经不够用了。聪明的祖先发明了进位制,逢十进一,开始懂得对数字进行编码,不同的数字代表不同的量。不过玛雅文明是使用二十进制的,相比于十进制,二十进制有很多不便之处,例如十进制只需要背诵九九表,二十进制要背的就是19*19的乘法表,难度更大。
描述数字最有效的是古印度人,他们发明了包括0在内的10个阿拉伯数字,就是今天全世界通用的数字,而且使用起来很方便。但是这种描述数字的方式是由阿拉伯人传入欧洲的,欧洲人将功劳给了“二道贩子”阿拉伯人。阿拉伯数字的革命性不仅在于它的简洁有效,而且标志着数字和文字的分离。这在客观上让自然语言的研究和数学在几千年里没有重合的轨迹,而且越走越远。
文字和语言背后的数学
从象形文字到拼音文字是一个飞跃,因为人类在描述物体的方式上,从物体的外表进化到抽象的概念,同时不自觉地采用了对信息的编码。
楔形文字就是一种拼音文字,每个形状不同的楔子实际上是一个不同的字母,这些字母经过腓尼基商人传播给希腊人的祖先,在不断发展后,古希腊文字母的拼写和读音已经紧密地结合起来了,这种语言相对容易学习,这些只需要几十个字母的语言成为了欧亚非大陆语言体系的主体,在今日,我们把所有西方的拼音文字成为罗马式的语言(Roman Langusages)。
还有罗马体系的文字和意型文字,大都常用字笔画少,而生僻字笔画多。这也符合信息论中的最短编码原理,这样带来的好处是书写起来省时间、省材料。
关于文字和数学的关系,在《圣经》中也有体现。《圣经》的写作持续了很多世纪,后世的人在做补充时,看到的是几百年前甚至上前年前原作的抄写本,那如何做到抄写尽量不出错呢?犹太人发明了一种类似校验码的方法:将每一个希伯来字母对应于一个数字,这样每行文字加起来便会得到一个特殊的数字,成为这一行的校验码。如果这一页每一行和每一列的校验码和原文完全相同,说明这一页无误。同样,只要找到某行某列的校验码不一致,就能确定哪个位置出错。这背后的原理跟我们今日所做的校验是类似的。
从规则到统计
过去大多数学者认为语言识别是根据规则进行匹配,理解自然语言,要分析语句和获取语义,在句法分析中,对一个简答的句子(例如:徐志摩喜欢林徽因。)进行分析,得出它的语法分析树🌲:

乍一眼好像还挺简单,就跟大学学的汇编语言类似(毕竟大学还没接触到更难的语法),简单程序的语法分析器。可这是中文语言,且随着句子的加长或者文字顺序调换后,根据文法规则生成的语法分析树就会更加复杂,而且句子的意思还要根据上下文进行确定,这就导致了需要更多的文法规则和说明各个规则特定的使用环境(越来越多和复杂)。
由于基于规则的句法分析(包括文法分析或者语法分析)的缺点,导致了另一种方法的诞生:统计语言学。采用基于统计的方法,IBM将当时的语音识别率从70%提升到90%,同时语音识别的规模从几百单词上升到几万单词,将语音识别从实验室带向实际应用打好了基础。
自然语言处理的专家贾里尼克提出一个观点:
一个句子是否合理,就看它的可能性大小如何。至于可能性就用概率来衡量。第一个句子出现的概率大致是$10^{-20}$,第二个句子出现的概率是$10^{-25}$,第三个句子出现的概率是$10^{-70}$。因此,第一个句子出现的可能性最大,是第二个句子的10万倍,第三个句子的一百亿亿亿亿亿亿倍。
这样的话,选择概率最大的作为语言识别的结果,会更加符合实际结果。基于统计的自然语言处理方法,在数学模型上和通信是相通的,从此,在数学意义上自然语言处理又与语言的初衷——通信联系在一起了。
最后说一句
里面还有更加高深的数学知识我还没能深入了解,例如离散数学、图论、概率论、高等数学、马尔可夫模型、状态机、数学模型、信息最大熵、自然语言处理和贝叶斯网络等等知识,没法很好给大家介绍。只能给大家献上我的膝盖🐢,先立个flag,之后去补相关知识~~
参考资料:
1:《数学之美》——吴军
2:百度百科