
事情回顾
上周五,通过Grafana监控,线上环境突然出现CPU和内存飙升的情况:

但是看到网络输入和输入流量都不是很高,所以网站被别人攻击的概率不高,后来服务器负荷居高不下,只能保存dump文件进行分析,并一台一台服务器进行重新启动(还好大家周五下班了)
通过日志分析
既然服务器在某个时间点出现了高负荷,于是就先去找一开始出现问题的服务器,去找耗时的服务,例如我当时去找数据库耗时的服务,由于上周的日志已经被刷掉,于是我大致描述一下:
1 | [admin@xxx xxxyyyy]$ grep '15:14:' common-dal-digest.log | grep -E '[0-9]{4,}ms' |
上述语句是查询在15:14那一分钟内,在common-dal-digest.log文件中,耗时超过1000ms的SQL服务(我上周查的是耗时超过10秒的服务)。
通过traceId去查Nginx保存的访问日志,定位在该时间点内,分发到该服务器上的用户请求。还有根据该traceId,定位到整个调用流程所使用到的服务,发现的确十分耗时…
于是拿到了该请求具体信息,包括用户的登录手机号码,因为这个时候,其它几台服务器也出现了CPU和内存负载升高,于是根据手机号查询了其它几台服务器的访问日志,发现同一个请求,该用户也调用了很多次…
使用mat进行dump文件分析
通过mat工具对dump文件进行分析,调查是什么请求占用了大内存:

观察了该对象的引用树,右键选择【class_ reference】,查看对象列表,和观察GC日志,定位到具体的对象信息。
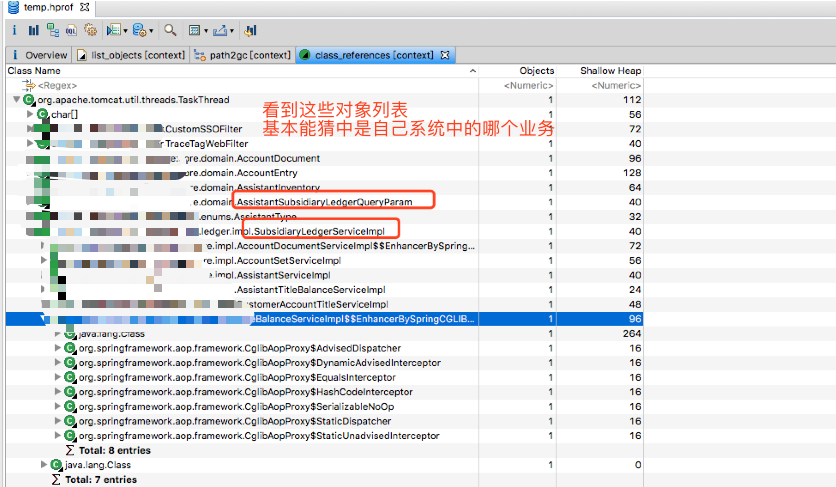
通过日志以及dump文件,都指向了某个文件导出接口,接着在代码中分析该接口具体调用链路,发现导出的数据很多,而且老代码进行计算的逻辑嵌套了很多for循环,计算效率低。
查询了该用户在这个接口的所调用的数据量,需要查询三个表,然后for循环中大概会计算个100w+次,导致阻塞了其它请求,线上的服务器CPU和内存使用情况一直飙升。
代码进行性能优化
在看到该业务在git提交记录是我上一年实习期写的时候,我的内心是崩溃的,当时对业务不熟悉,直接循环调用了老代码,而且也没有测试过这么大的数据量,所以GG了。
然后我就开始做代码性能优化,首先仔细梳理了一下整个业务流程,通过增加SQL查询条件,减少数据库IO和查询数据量,优化判断条件,减少for嵌套、循环次数和计算量。
通过jvisualVM进行对比
对比新老代码所占用的CPU和内存状态
优化前:

优化后:
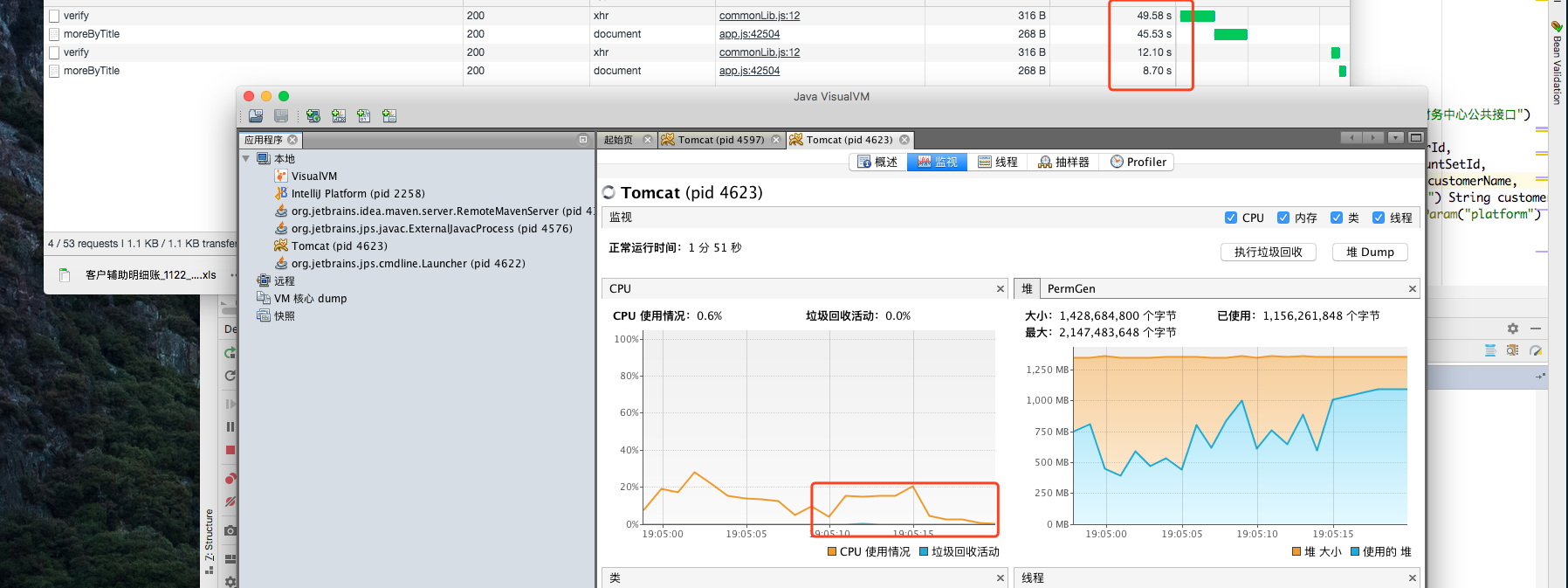
通过上述优化之后,计算1w条数据量进行导出,在老代码需要48s,新代码也要8s ,不过这是大数据量的情况下,实际用户的数据没有这么多,所以基本上满足了线上99%的用户使用。
,不过这是大数据量的情况下,实际用户的数据没有这么多,所以基本上满足了线上99%的用户使用。
当然,由于这些数据是本地开发环境新增加的,与出现OOM问题的用户数据量还有些差别,但通过优化后的代码,已经在数据库查询的时候就过滤掉很多无效的数据,在for循环计算前也加了过滤条件,所以真正计算起来起来就降低了很多计算量。
恩,自己优化好了,还要等测试爸爸们测试后才敢上线,这次要疯狂造数据
开发注意点
在开发一开始的时候,都没有考虑到性能问题,想着满足需求就完成任务,但数据量一大起来,就有可能出现这些OOM问题,所以以后开发时,需要考虑一下几点:
- 梳理设计流程
- 考虑是否有性能问题
- 与产品经理商量控制查询条件,减少查询的范围
- 与数据库交互时,减少无效的查询,合并查询和合并更新操作
- 减少for循环,尤其注意for循环嵌套问题!
- 调用老代码要看注意=-=
吐槽
万元预算玩新机 还有沈大妈的表情真好玩,直接拿来用了~