
周四晚上,有一台服务器遇到一个很怪异的现象:有流量访问时,CPU负载升到100%,但是内存使用量不大,通过NGINX切流,不接受HTTP请求,服务器又自动恢复了,原本打算准时游泳的脚步,就被问题缠住了=-=
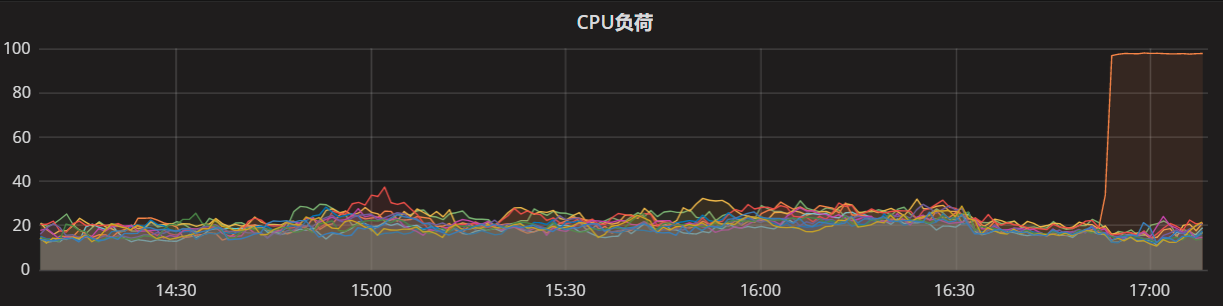
于是我们就开始登陆有问题的服务器,通过日志和监控查看具体问题。在这切流前后,ActiveMQ消息服务和DUBBO的RPC调用,都是处于运行中的,区别在于,切流前的CPU负载突然升高到100%,但是内存使用量只是升高,没到OOM的地步(所以没有dump文件)。
开始查看服务器:
1:通过top服务器,定位到PID为30284的jvm进程占用CPU到达100%
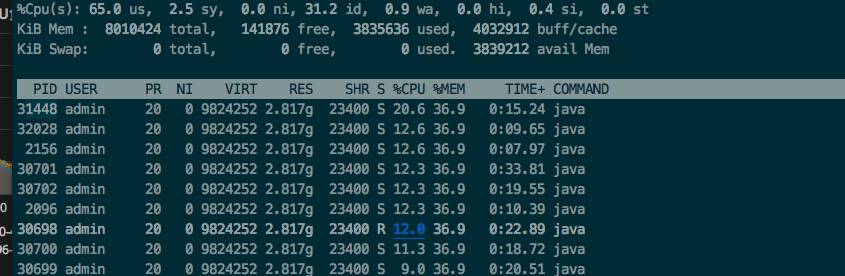
2:显示线程列表,按照CPU占用高的线程排序
[admin@xxxxx]# top -Hp 30284
3:找到最耗时线程的PID,然后将它转成16进制的格式
[admin@xxxxx]# printf “%x\n” 31448
77e0
4:通过jstack命令查看jvm,grep耗时线程的详细堆栈信息
[admin@xxxx] # jstack 30284 | grep 77e0 -A 60

进一步分析
堆栈信息比较多的是MQ线程处于TIME_WAIT状态,等待消息出队,通过观察源码,发现这里一直在计算,不过MQClient一直在要等待消息处理,所以这个状态好像也没啥问题=-=

通过查看业务日志,发现消息消费onMessage特别耗时
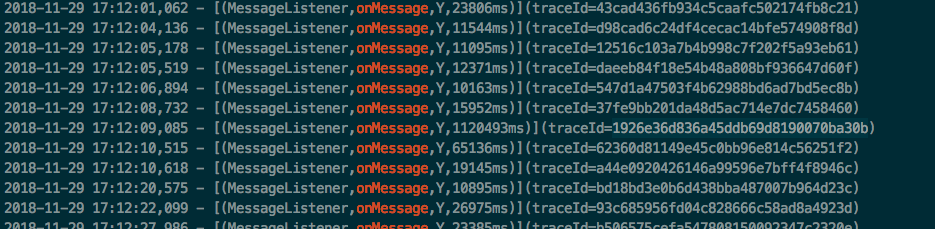
有些消息处理已经超过100000ms,根本算不上正常(ಥ_ಥ),对比与其它几台服务器,同样的应用,但消息处理速度很正常,其它各项指标也是正常,只能先将这台服务器切流,初步怀疑这台服务器的MQ消费有特殊的问题 。
另外跟踪几个消费的消息,发现有个数据库查询方法特别耗时,导致整个消息处理变慢

查看其它服务器的消息处理情况,这个查询方法速度虽然也要一到两秒,但也算是正常。但这台机器查询速度慢应该是受到服务器CPU高负载的影响,毕竟redis和JDBC连接也会受到影响。
将这台服务器暂时切下,等待消息处理结束,服务器就自动恢复了,但是是什么引起服务器的CPU负载升高的“元凶”还没找到,怎么也解释不通,还需要继续观察。
小结:
1、学习到简单定位占用CPU高的线程在做什么操作的服务器命令
2、ActiveMQ这个消息中间件还是不熟悉,需要去了解一下
3、dao层查询慢,业务上需要进行优化这个场景
4、要去了解服务器各种状态的影响